So, I'm risking coming off presumptuous in pitching a description of an SOA stack. But it's only a logical model to establish some boundaries between some (I think) obvious and independent concerns. There is quite a lot of discussion yet to come about SOA and this model could make for a handy map.
There are 4 basic layers separating the concerns of the Canonical SOA stack. At the bottom, quite expectedly, are application components which reside in a layer call the application domain. Next up the stack is the agent layer, which I think is at the heart of SOA. The agent layer is accessed by any number of representation channels which are endpoints with specific wire formats, invocation protocols, and service description flavors. At the top of the stack are conversation managers that provide for situations that span multiple invocations of service actions and probably have some state for managing conversation instances (sorry about the image quality - I'll get the hang of it).

I think this description is a simple as possible, although the top and bottom pairs of layers each form their own conspiracies. The bottom two layers compose functional capabilities to create callable service actions. The top two layers rationalize service actions into invocation models – stateless (e.g., SOAP, REST, proprietary mechanisms) and stateful (UI controllers, Orchestration Engines, etc.). This bears repeating: The bottom two layers formulate the solution's functionality by splitting requirements into two special categories. The top two layers provide the loose coupling and transport flexibility.
Application Domains and Agents
One tenet (ugh - the "t" word) of designing applications for an SOA is to segregate capabilities from policies when analyzing functional requirements. This is because we are betting that policies frequently change over time – at least more frequently than our capabilities need to evolve. So we want to isolate the hand-built code to the area of the solution that both seldom changes and tends to implement requirements that are tough to implement declaratively. Conversely, the bits that change most often are the collaborations and transforms that reflect business policies between functional areas.
As an example, not much has changed in the way debts and credits work in quite a while (except possibly at Enron). But the business processes that ultimately drive accounting transactions do change frequently. Agility (again, Enron notwithstanding) is valuable. For a packaged software company, having agile business processes in your products is these days is a competitive requirement.
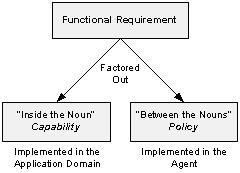 Confession: I’m old-fashioned and still prefer nouns when describing an application domain.
Confession: I’m old-fashioned and still prefer nouns when describing an application domain.
Suppose a functional requirement dictates that when a sales order is confirmed, the order value must be recalculated, the order tables must updated and the inventory available-to-promise (ATP) balances must be adjusted. The rule requiring that the two nouns – sales order and inventory – collaborate shouldn’t be implemented in the order confirmation code. But you would be surprised how often collaboration is imperatively nested inline with the functional code. This means that policy changes require core code changes. Over time, you wind up with spaghetti.
The idea of factoring functions and collaborations from requirements is a classic concept commonly depicted in UML sequence diagrams. In SOA, the agent layer is responsible for executing collaborations. So collaboration logic needs to be extricated from the functional logic. I’m trying to stay away from specific design choices for now, but it makes sense to me to leverage the heck out of metadata in the agent layer. The more metadata you have and the richer it’s content, the more the agent can do as an engine. That means less hand-rolled code.
The ideal agent needs to be a fast, micro-orchestration engine that can validate messages, create transformations, execute application components, and delineate transactional and asynchronous boundaries. It’s a tall order, but the emergence of a robust agent layer coupled with stringent (yet simpler) coding practices is really the lynchpin of SOA.
Representation Channels and Conversation Managers
A representation channel is a mechanism providing access to service actions. Channels not only specify wire formats, but are also responsible for publishing descriptions of the service action set. Interoperability is achieved (in theory) when channels comply with industry standards like SOAP, SMTP, etc.
Some protocols and wire formats cannot convey the complete set of service actions. So it’s important to know where a service design might have difficulties with some channels in conveying the semantic intent (distinguishing what service you are calling) or the physical data (video streams over SOAP). It's important – and most people have already concluded this – that the presence of any specific communications channel does not an SOA make. You choose your set of data representation channels based on your anticipated caller patterns. Not all channels can handle all service actions.
The bottom three layers of the Canonical SOA Stack revolve around statelessness. If you look at BizTalk orchestrations or user interfaces, there is often a notion of a conversation instance (or session). Also, such facilities at the edges often need to aggregate and shred data for their own specific purposes. It might not be cost-justified to incorporate these requirements all the way down the stack.
The top of the stack – the conversation managers – implements stateful conversations that rely on the stateless model beneath. There is room for debate here because stateful conversation managers can just as easily connect directly to the agent layer. Maybe the top two layers ought to be merged, but for now I’m more comfortable leaving them separate. Let me know your thoughts!
Examples of conversation managers might include BizTalk orchestrations, user interface services, and pub/sub data staging. There are lots of facilities you could consider a conversation manager or a representation channel. Some channels are dedicated to a specific conversation manager. One example would be a publish/subscribe data staging area. Occasionally-connected clients – like Outlook on a notebook computer – also have custom conversation managers to stream just enough data to and from the server.
Summary
Many people think of service-orientation as fractal architecture, meaning that what one SOA domain might consider, an application component is really another SOA domain. This is sort of the Horton Hears a Who philosophy. Sure, inter-SOA-domain calls can happen in at least 3 of the 4 layers (not sure about channels). But this SOA description stays in it's own borders, for now, to keep the tiers clear.
Anyway, I wanted to start grounding the conversation about SOA and thought this would be helpful. At some point, someone is going to ask us to build a proper an SOA. I, for one, would like to be able to open Eclipse or Visual Studio some day and sort of know what to do next. Maybe having some named tiers can help propel design discussions. I think some interesting work is ahead to find metadata pathways from the bottom to the top of the SOA Stack. Such pathways host the transformation patterns I described in the last post.
No comments:
Post a Comment